소개
Spark스터디에 참여할 수 있는 좋은 기회가 생겼다.
아래의 책을 여러 명이 읽어보고 정리하면서 서로의 생각을
공유하는 스터디 이며 그 첫 장을 여는 포스팅.
많이 부족하고 처음 작성해 보는 포스팅이라 서툴 수 있는데
열심히 노력해서 다른 분들처럼 멋있는 글을 써보고 싶덩
Keywords & Terms
- HDFS(Hadoop Distributed File System)
- YARN(Yet Another Resource Negotiator)
- data locality, shared nothing, map-reduce
- schema-on-write <-> schema-on-read
- RDD(Resilient Destributed Dataset)
- fault-tolerant 내결함성
Summary
책은 8 Chapter지만, 2 Part로 나눌 수 있음.
Part 1 - 스파크 기초 (ch.1 ~ ch.4)
Part 2 - 스파크 응용 (ch.5 ~ ch.8)
1장에서는
- Big Data, Hadoop 소개
- HDFS, YARN 소개
- Spark 소개
- PySpark에 필요한 Python 기본
을 설명하는 챕터
PySpark
이걸 왜 써요 ? 라는 사람들에게 하는 좋은 비유
예전에는 무거운 짐을 싣기 위해서 소를 이용했는데,
한 마리의 소를 이용해서 짐을 싣을 수 없을 경우에는
더 힘이 센 소를 찾기 보단
여러 마리의 소를 이용해 짐을 옮기는 방법이 효율적이지 않나?
빅데이터도 그렇다 - 그레이스 호퍼 제독
ㄴ Big Data, Hadoop
ㄴㄴ 빅데이터와 하둡의 탄생
2000년대 구글, 야후가 시작 한 싸움 ->
구글은 2003년에 더 구글 파일 시스템 이라는 논문을 시작으로
2004년에 Map-Reduce 논문을 발표함 이게 추후의 Hadoop의 시초 ->
야후가 2006년 공식적 Hadoop을 채택하고 구글의 인적자원을 가져감
ㄴㄴ Hadoop?
Hadoop은 데이터 지역성이라는 개념에 바탕을 둔 데이터 저장 및 처리 플랫폼이다
=> 책에서는 저렇게 정의를 했는데 내 식으로 다시 정의해보면
큰 문제(데이터)를 작은 문제(데이터)로 나눠서 저장 및 문제를 해결하려는
좋은 도구 같음
데이터지역성(data locality)(이)란 데이터를 호스트로 보내 처리하는 기존 방식과 달리,
데이터가 있는 곳으로 이동해서 계산하는 데이터 처리방식임(오? 신박함)
각 Node는 다른 Node들과 통신 할 필요없이 전체 데이터의 훨씬 작은 부분을 독립적으로
처리하면서 분산 파일 시스템의 구현을 통해 해결함
이걸 가능하게 하는 게 비공유 접근(shared nothing)개념schema-on-read시스템으로 스키마가 따로 없기에 광범위한 데이터를 저장하고 처리 할 수 있는게 특징임
ㄴㄴ Component of Hadoop
- HDFS(Hadoop Distributed File System) : 하둡의 스토리지 서브시스템
- YARN(Yet Another Resource Negotiator) : 하둡의 프로세싱 또는 리소스 스케줄링 서브시스템
- Flume, Sqoop = 데이터 처리 프로젝트
- Pig, Hive = 데이터 분석 툴
하둡과 상호 작용하거나 통합하는 프로젝트를 하둡에코시스템 이라고 함.
*근데 스파크는 하둡을 실행 할 필요가 없어서 에코시스템인지 논란의 여지가 있음
ㄴ HDFS, YARN 소개
ㄴㄴ HDFS
클러스터의 하나 이상의 노드에 파일이 분산되어 있는 블럭으로 구성된 가상 파일 시스템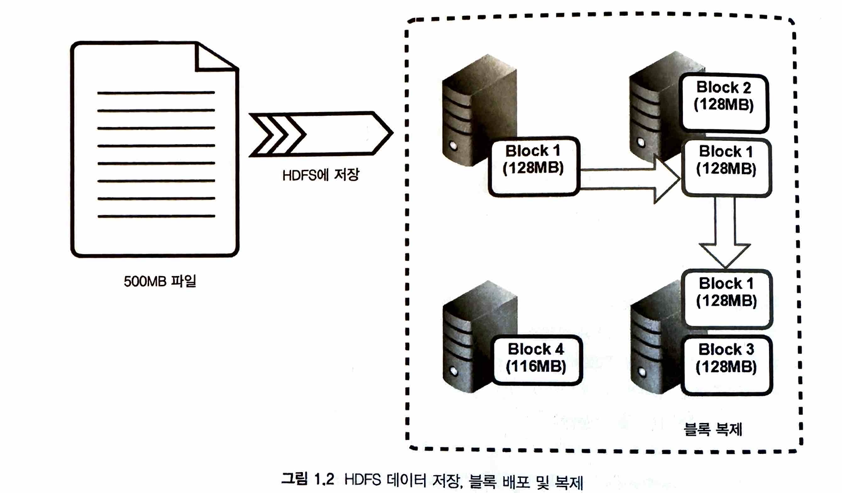
적재 프로세스 설명
- Ingestion 프로세스는 설정한 블록크기에 따라 파일을 나눔
- 노드 간 분산 및 복제해서 fault-tolerance 달성하고 로컬에서 처리
- HDFS블록은
DN:데이터노트라는 슬레이브 노드에 저장 및 관리됨 - 이런 정보들은
NN:네임노드라는 HDFS 마스터 노드 상주 메모리에MD:메타데이터로 저장 네임노드는 RDB 트랜잭션로그처럼 저널링함수를 통해메타데이터위치 제공(맵핑테이블 느낌)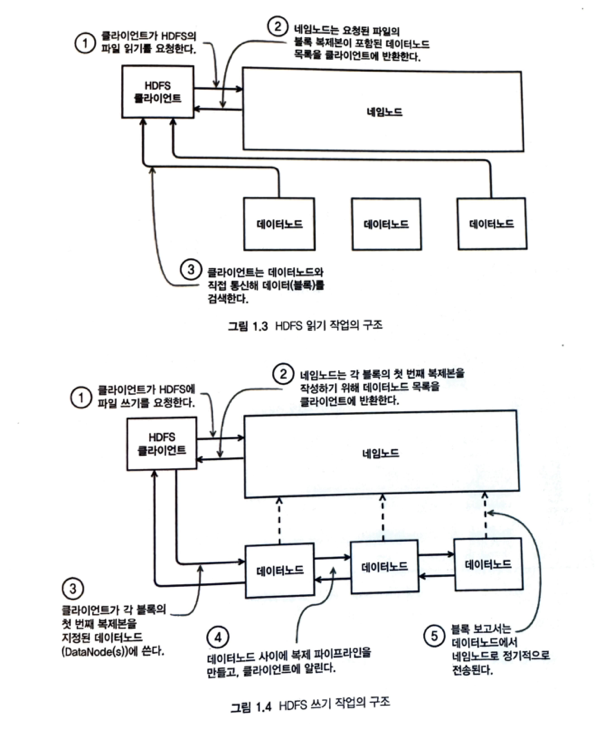
ㄴㄴ YARN
YARN은 Hadoop의 데이터를 처리하고 스케쥴링하는 역할
뜻이 궁금해서 쳐봤는데
“Yet another”는 일반적으로 이미 많은 것들이 존재하고 있는 상황에서 추가로 하나를 가리키는 표현입니다. 따라서 “yet another resource negotiation”은 이미 다른 자원 협상이 있었음에도 불구하고 추가로 하나가 이루어지고 있다는 의미를 갖는다고 합니다
설명하는 도식은 아래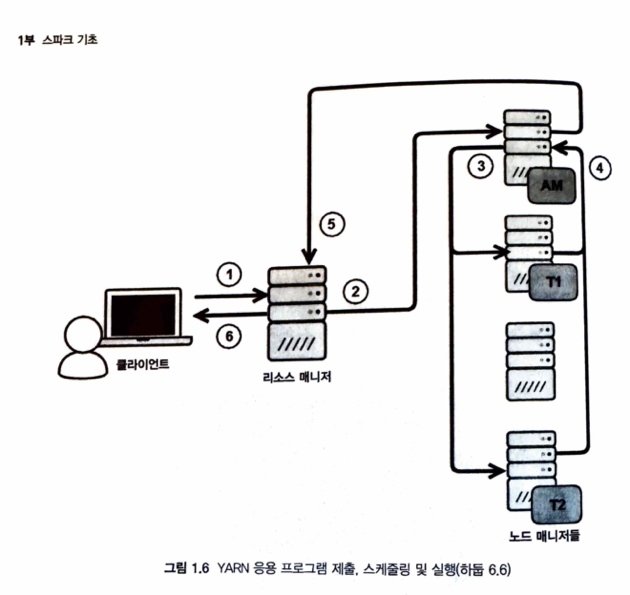
순서를 설명하면
- 1) 클라이언트 ->
리소스 매니저작업 시킴 - 2)
리소스 매니저는노드매니저에게,애플리케이션 마스터(AM)을 할당 - 3)
AM은 실행할 작업컨테이너 협상하고 관리할노드매니저로 전달 - 4)
노드매니저는 (2)의AM에게 보고 - 5)
AM은 (1)의리소스매니저에게 보고 - 6)
리소스 매니저는 클라에게 보고 - 자세한건 3장에 있음
보통 8088에 웹 UI를 제공
ㄴ Spark 소개
Hadoop의 맵리듀스 구현에 대안으로 만들어져 매우 효율적이라고 함
특징
- 맵리듀스를 대체할 수 있는 리소스 스케줄링, 오케스트레이션 시스템을 검토하도록 설계
- 맵리듀스 대안으로 스파크는 RDD(Resilient Destributed Dataset) 탄력적인 분산 데이터 집합이라고 분리는 분산형, 내결함성(fault-tolerant), 인메모리 구조를 구현
- 스칼라로 작성되어있고 JVM에서 실행됨
- 파이썬이랑 스칼라 인터프리터식으로 쿼리가능
- Hadoop의 데이터 처리 프레임워크로 Spark를 배포할 수 있음(일반적으로는 HDFS 인데)
ㄴ PySpark를 위한 기초 python
여기서는 어느정도 python을 안다고 가정하고 다른 부분만 기술함
- 스파크RDD list 객체는 변경이 안됨
- tuple은 같은데, Spark에선 키/값 쌍으로 많이 쓴다고함(? 왜 dict냅두고)
- dict는 RDD에서 고정객체로 쓸수 있다고 함(? 고정객체는 뭐지)
- 피클은 파이썬의 특징적인 직렬화 메소드, Json 보다 빠른데 PySpark에서 많이 프로세스간 데이터 전송하는데 많이 쓴다고함
- 익명함수 & Lambda를 많이 쓴다고 함 실제 예는 아래에 기술
- 클로저함수도 많이 씀, 분산환경에서 중요한 이점을 가질 수 있다는데 함수 구성에따라 오히려 독이 될수도 있다고함 대략 파일을 읽고 띄어쓰기단위로 split했을때 len()이 1개이상인 애들을 필터링해서
1
2
3
4
5
6
7lines = sc.textFile("YOUR/DIR/FILE")
counts = lines.flatMap(lambda x: x.split(' ')) \
.filter(lambda x: len(x) > 0) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x, y: x+y) \
.collect()
)
reduce하는 느낌이네
Why?
위 챕터랑 정리를하면서 궁금증이 남는 것 + 알아봤으면 좋겠는 걸 따로 기록
- [ ] 왜 굳이 같은 데이터(블록)을 복제해서 저장할까? 유실될까 걱정? 아니면 블록체인식의 저장방법인건지
- [ ] 그렇다면 몇개까지 복제하는게 최적화된 복제블록일까? 너무 많으면 오버해서 저장하는 거 같고 너무 적으면 나누는 의미가 있을까 싶은데 이것도 국룰적인 복제개수가 존재할까 ?
- [ ] 클로저 펑션을 왜 써야하는지 사실 이해가 되진않음. 이게 왜 분산된환경에서 쓰면 이점이 있으려나
Next
다음은 위의 Why세션에 대한 조사와,
2장 스파크 배포 에 대해서 포스팅 할 예정입니다 ~
Copyright © 2024 박홍(박형준, DevHyung).